Администратор закрепил это сообщение

🇮🇹 IT
Trattoria storica della zona Garda cerca personale di sala.
Annuncio verificato.
🇩🇪 DE
Traditionelle Trattoria am Gardasee sucht Servicepersonal.
Verifizierte Anzeige.
🇬🇧 EN
Traditional trattoria in the Garda Lake area is looking for service staff.
Verified listing.
🇷🇺 RU
Традиционная траттория в районе озера Гарда ищет персонал в зал.
Объявление проверено.
🇲🇩 MD (RO)
Trattorie tradițională din zona Lacului Garda caută personal de sală.
https://www.trattoriavilla...
Trattoria storica della zona Garda cerca personale di sala.
Annuncio verificato.
🇩🇪 DE
Traditionelle Trattoria am Gardasee sucht Servicepersonal.
Verifizierte Anzeige.
🇬🇧 EN
Traditional trattoria in the Garda Lake area is looking for service staff.
Verified listing.
🇷🇺 RU
Традиционная траттория в районе озера Гарда ищет персонал в зал.
Объявление проверено.
🇲🇩 MD (RO)
Trattorie tradițională din zona Lacului Garda caută personal de sală.
https://www.trattoriavilla...


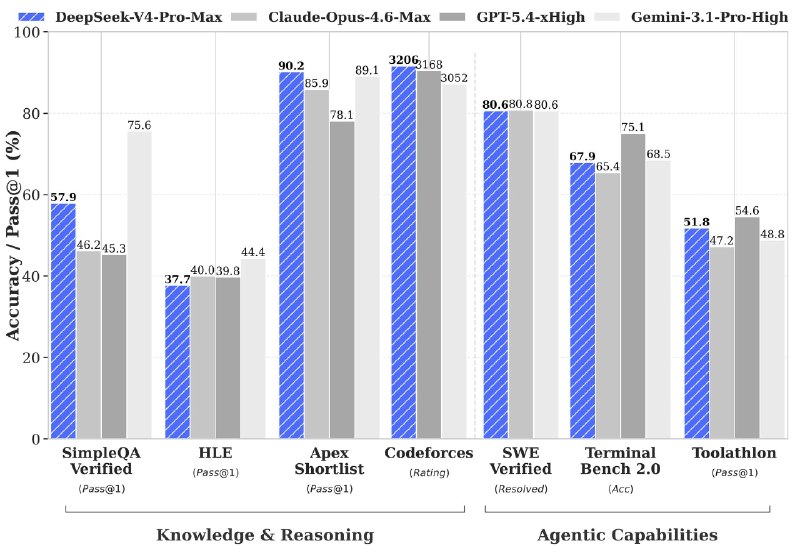
🇨🇳 DeepSeek just open-sourced a 1.6T AI model built for coding agents and million-token memory
DeepSeek unveiled its V4 generation with two new foundation models: DeepSeek-V4-Pro (1.6 trillion parameters, activating only 49B per token) and DeepSeek-V4-Flash (284B parameters focused on efficiency). The release pushes open-source AI closer to the frontier dominated by closed labs.
What makes V4 different:
• Introduces DeepSeek Sparse Attention (DSA), a new architecture designed to cut memory and compute costs.
• Uses token-wise compression, allowing far longer context windows without the usua
DeepSeek unveiled its V4 generation with two new foundation models: DeepSeek-V4-Pro (1.6 trillion parameters, activating only 49B per token) and DeepSeek-V4-Flash (284B parameters focused on efficiency). The release pushes open-source AI closer to the frontier dominated by closed labs.
What makes V4 different:
• Introduces DeepSeek Sparse Attention (DSA), a new architecture designed to cut memory and compute costs.
• Uses token-wise compression, allowing far longer context windows without the usua
Right now, compute is everything..
Anthropic does not have enough of it, which is why opus performance is degrading.
OpenAI felt the pressure in 2025, especially after the Ghibli wave, which pushed sam to lock in long-term compute. Until there is a breakthrough in model architecture or chip design, this cycle will continue.
aipost 🏴
Anthropic does not have enough of it, which is why opus performance is degrading.
OpenAI felt the pressure in 2025, especially after the Ghibli wave, which pushed sam to lock in long-term compute. Until there is a breakthrough in model architecture or chip design, this cycle will continue.
aipost 🏴

⚡️ Runway has unveiled a massive breakthrough in AI video generation at NVIDIA's GTC event, showcasing a new model capable of generating high-definition video in genuine real-time.
The new model boasts a "time-to-first-frame" of under 100 milliseconds. This means HD video begins generating and playing almost the instant a command is given.
This research preview was co-developed with NVIDIA and runs on their newly announced Vera Rubin architecture. This real-time capability is a foundational step for Runway's General World Model (GWM-1). It pushes the technology beyond simple video generation
The new model boasts a "time-to-first-frame" of under 100 milliseconds. This means HD video begins generating and playing almost the instant a command is given.
This research preview was co-developed with NVIDIA and runs on their newly announced Vera Rubin architecture. This real-time capability is a foundational step for Runway's General World Model (GWM-1). It pushes the technology beyond simple video generation

🔥 Kimi AI introduces Attention Residuals, a new way to rethink how neural networks use past layers
Researchers at Moonshot AI just proposed a new architecture tweak that could make large AI models more efficient and smarter about how they use information from earlier layers. Instead of the traditional residual connections used in deep networks, they introduce Attention Residuals, a system where each layer can selectively attend to representations from previous layers.
Here’s what’s new:
Attention over past layers:
• Traditional residuals simply add outputs from earlier layers in a fixed way
Researchers at Moonshot AI just proposed a new architecture tweak that could make large AI models more efficient and smarter about how they use information from earlier layers. Instead of the traditional residual connections used in deep networks, they introduce Attention Residuals, a system where each layer can selectively attend to representations from previous layers.
Here’s what’s new:
Attention over past layers:
• Traditional residuals simply add outputs from earlier layers in a fixed way

🔥 Kimi AI introduces Attention Residuals, a new way to rethink how neural networks use past layers Researchers at Moonshot AI just proposed a new architecture tweak that could make large AI models more efficient and smarter about how they use information…
⚡️NVIDIA unveiled its first AI supercomputer integrating Groq racks alongside the Vera Rubin platform.
The system combines Rubin GPUs for memory-heavy workloads with Groq’s architecture for fast token generation to reduce inference latency and scale AI factories.
aipost 🏴
The system combines Rubin GPUs for memory-heavy workloads with Groq’s architecture for fast token generation to reduce inference latency and scale AI factories.
aipost 🏴

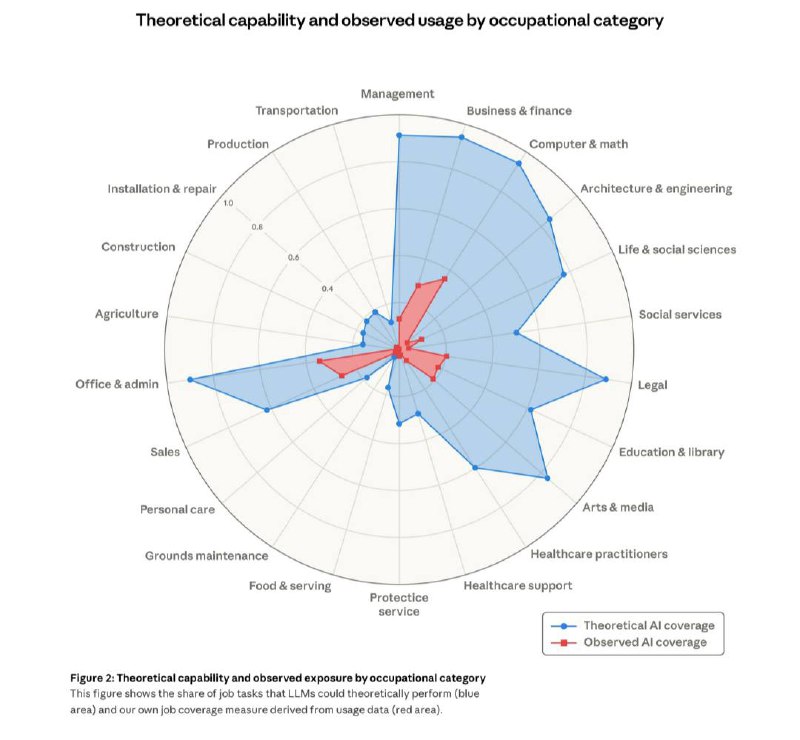
⚠️Anthropic just studied which jobs AI can theoretically replace vs. which ones it's actually automating right now.
Computer & math: 94% exposed. Legal: ~90%. Management, architecture, arts & media: all 60%+. Observed usage so far? A fraction of that.
But the gap is closing fast. Every field where the blue line towers over the red is borrowed time. Grounds maintenance and construction are sitting at near-zero on both.
Might be a good year to learn landscaping!
https://www.anthropic.com/...
aipost 🏴
Computer & math: 94% exposed. Legal: ~90%. Management, architecture, arts & media: all 60%+. Observed usage so far? A fraction of that.
But the gap is closing fast. Every field where the blue line towers over the red is borrowed time. Grounds maintenance and construction are sitting at near-zero on both.
Might be a good year to learn landscaping!
https://www.anthropic.com/...
aipost 🏴
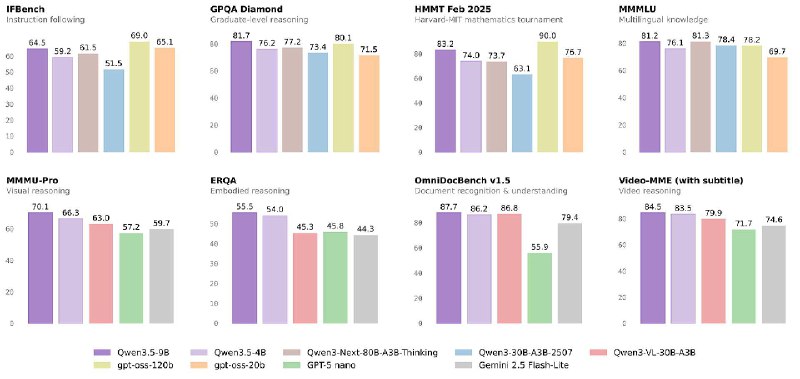
🚀 Alibaba group expands Qwen3.5 with ultra-efficient small models
Alibaba has introduced the Qwen 3.5 Small Model Series, a new lineup designed to deliver stronger intelligence with significantly lower compute requirements.
The release includes four compact models: Qwen3.5-0.8B · Qwen3.5-2B · Qwen3.5-4B · Qwen3.5-9B
Built on the Same Qwen3.5 Foundation
All models inherit the core architecture of the Qwen3.5 family:
• Native multimodal capabilities
• Improved model architecture
• Scaled reinforcement learning (RL) training
• Better efficiency per parameter
This isn’t a stripped-down versio
Alibaba has introduced the Qwen 3.5 Small Model Series, a new lineup designed to deliver stronger intelligence with significantly lower compute requirements.
The release includes four compact models: Qwen3.5-0.8B · Qwen3.5-2B · Qwen3.5-4B · Qwen3.5-9B
Built on the Same Qwen3.5 Foundation
All models inherit the core architecture of the Qwen3.5 family:
• Native multimodal capabilities
• Improved model architecture
• Scaled reinforcement learning (RL) training
• Better efficiency per parameter
This isn’t a stripped-down versio
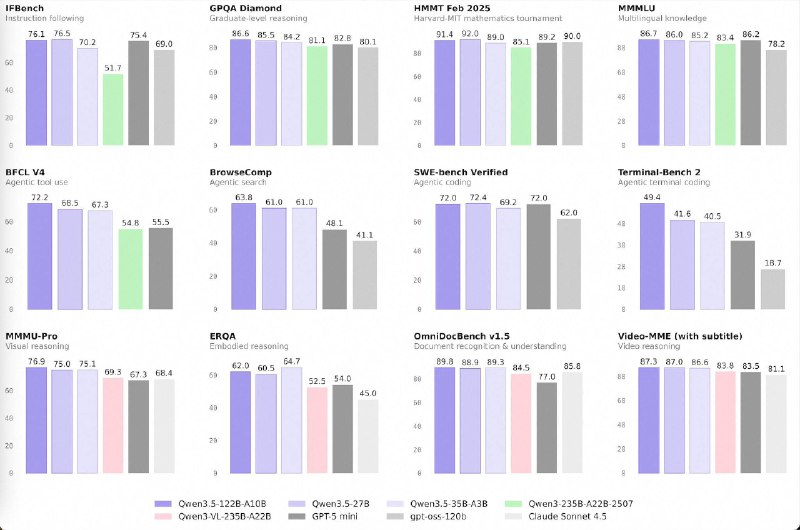
🚀 Qwen 3.5: Frontier intelligence without frontier size
Alibaba Group just released the Qwen 3.5 Medium model series and it’s a clear signal that smarter architecture is beating brute-force scale.
Lineup:
• Qwen3.5-Flash
• Qwen3.5-35B-A3B
• Qwen3.5-122B-A10B
• Qwen3.5-27B
What changed?
• 35B-A3B now outperforms previous 235B-class Qwen 3 models. Smaller model. Better results. Architecture + data quality + RL > raw parameter count.
• 122B and 27B are closing the gap between medium-sized models and frontier systems — especially in multi-step agent workflows.
This is the “efficiency era” of A
Alibaba Group just released the Qwen 3.5 Medium model series and it’s a clear signal that smarter architecture is beating brute-force scale.
Lineup:
• Qwen3.5-Flash
• Qwen3.5-35B-A3B
• Qwen3.5-122B-A10B
• Qwen3.5-27B
What changed?
• 35B-A3B now outperforms previous 235B-class Qwen 3 models. Smaller model. Better results. Architecture + data quality + RL > raw parameter count.
• 122B and 27B are closing the gap between medium-sized models and frontier systems — especially in multi-step agent workflows.
This is the “efficiency era” of A
🚀 Qwen3.5-397B-A17B: Open-Weight, Multimodal, Agent-Ready
Alibaba’s Qwen team just released the first open-weight model in the Qwen3.5 series built specifically for real-world AI agents.
What stands out:
• Native multimodal, text + image understanding out of the box
• Hybrid linear attention + sparse MoE architecture
• Large-scale RL environment scaling
• 8.6x–19.0x faster decoding vs Qwen3-Max
• Supports 201 languages & dialects
• Apache 2.0 license
Open weights + high throughput + permissive licensing = serious pressure on closed model providers.
Dive in:
• GitHub: https://github.com/Qw
Alibaba’s Qwen team just released the first open-weight model in the Qwen3.5 series built specifically for real-world AI agents.
What stands out:
• Native multimodal, text + image understanding out of the box
• Hybrid linear attention + sparse MoE architecture
• Large-scale RL environment scaling
• 8.6x–19.0x faster decoding vs Qwen3-Max
• Supports 201 languages & dialects
• Apache 2.0 license
Open weights + high throughput + permissive licensing = serious pressure on closed model providers.
Dive in:
• GitHub: https://github.com/Qw

UK-based startup 'Humanoid' announced KinetIQ, an AI framework with a Vision-Language-Action (VLA) model at its core.
It uses a four-layer architecture: fleet orchestration, task decomposition, VLA, and RL for whole-body control. It works on both bipedal and wheeled robots.
aipost 🏴
It uses a four-layer architecture: fleet orchestration, task decomposition, VLA, and RL for whole-body control. It works on both bipedal and wheeled robots.
aipost 🏴

⚡️NVIDIA just removed the biggest friction point in Voice AI
They've open-sourced PersonaPlex-7B, a full-duplex conversational model that can listen and speak at the same time.
Instead of waiting for you to finish talking, it uses a dual-stream architecture to process and respond in real-time. 100% Open-Source and Free.
https://github.com/NVIDIA/...
aipost 🏴
They've open-sourced PersonaPlex-7B, a full-duplex conversational model that can listen and speak at the same time.
Instead of waiting for you to finish talking, it uses a dual-stream architecture to process and respond in real-time. 100% Open-Source and Free.
https://github.com/NVIDIA/...
aipost 🏴

The US moat is melting, Demis Hassabis, the CEO of Google DeepMind told CNBC.
"China's artificial intelligence models may be just "a matter of months" behind U.S. and Western capabilities.
Chinese AI models are closer to U.S. and Western capabilities "than maybe we thought one or two years ago." The only thing China still lacks is the ability to explore its own breakthroughs, such as Transformer architecture. For now.
aipost 🏴
"China's artificial intelligence models may be just "a matter of months" behind U.S. and Western capabilities.
Chinese AI models are closer to U.S. and Western capabilities "than maybe we thought one or two years ago." The only thing China still lacks is the ability to explore its own breakthroughs, such as Transformer architecture. For now.
aipost 🏴

📢 OpenAI is preparing to release a new audio model in connection with its upcoming standalone audio device!
OpenAI is aggressively upgrading its audio AI to power a future audio-first personal device, expected in about a year. Internal teams have merged, a new voice model architecture is coming in Q1 2026, and early gains include more natural, emotional speech, faster responses, and real-time interruption handling - key for a companion-style AI that proactively helps users.
Source.
aipost 🏴
OpenAI is aggressively upgrading its audio AI to power a future audio-first personal device, expected in about a year. Internal teams have merged, a new voice model architecture is coming in Q1 2026, and early gains include more natural, emotional speech, faster responses, and real-time interruption handling - key for a companion-style AI that proactively helps users.
Source.
aipost 🏴

🗣Geoffrey Hinton says there's still major progress left just from better engineering, not just new science
DeepSeek is a clear example: smarter training and more efficient use of older NVIDIA chips can deliver strong results with less compute and energy. "We'll see new architectures we haven't even imagined yet"
aipost 🏴
DeepSeek is a clear example: smarter training and more efficient use of older NVIDIA chips can deliver strong results with less compute and energy. "We'll see new architectures we haven't even imagined yet"
aipost 🏴

🗣Sergey Brin admits Google messed up by under-investing in the transformer architecture it invented
Google was too scared to release chatbots that "say dumb things", so it under-invested in scaling compute. "We didn't take it very seriously... and openAI ran with it"
AI Post ⚪️ | Our X 🏴
Google was too scared to release chatbots that "say dumb things", so it under-invested in scaling compute. "We didn't take it very seriously... and openAI ran with it"
AI Post ⚪️ | Our X 🏴

Cybersecurity researchers have uncovered a critical vulnerability in the architecture of large language models underpinning generative AI, but how dangerous is this flaw? https://www.livescience.co...

🔔 Big breakthrough in scientific reasoning
New AI system - SciAgent exceeds human gold medalists on several Science Olympiads, using one unified architecture.
There are no discipline specific modules. Just pure cross domain scientific reasoning. The implications for research automation and multi domain AI reasoning are enormous.
AI Post 🪙 | Our X 🥇
New AI system - SciAgent exceeds human gold medalists on several Science Olympiads, using one unified architecture.
There are no discipline specific modules. Just pure cross domain scientific reasoning. The implications for research automation and multi domain AI reasoning are enormous.
AI Post 🪙 | Our X 🥇

Huge AI news from Google
Google Research just unveiled a bold new ML paradigm that views a model as a stack of nested problems so it can keep learning new skills forever without forgetting the old ones, a huge leap toward AI that actually evolves like a brain.
On tests of language modeling, long context reasoning and continual learning, Hope (self modifying architecture) outperformed traditional transformer architectures and older methods.
Big progress
Details. Paper.
AI Post 🪙 | Our X 🥇
Google Research just unveiled a bold new ML paradigm that views a model as a stack of nested problems so it can keep learning new skills forever without forgetting the old ones, a huge leap toward AI that actually evolves like a brain.
On tests of language modeling, long context reasoning and continual learning, Hope (self modifying architecture) outperformed traditional transformer architectures and older methods.
Big progress
Details. Paper.
AI Post 🪙 | Our X 🥇

🔥 Grok just leveled up quietly
xAI silently rolled out a patch for Grok-4-Fast, and the jump in performance is dramatic.
🧠 Reasoning mode completion rate: 77.5% → 94.1%
⚡ Non-reasoning mode: up to 97.9% complete responses
The secret? Smarter system prompt injections, no architecture overhaul, just sharper guidance.
No hype, no announcement, just real, measurable gains in Grok’s reliability.
AI Post 🪙 | Our X 🥇
xAI silently rolled out a patch for Grok-4-Fast, and the jump in performance is dramatic.
🧠 Reasoning mode completion rate: 77.5% → 94.1%
⚡ Non-reasoning mode: up to 97.9% complete responses
The secret? Smarter system prompt injections, no architecture overhaul, just sharper guidance.
No hype, no announcement, just real, measurable gains in Grok’s reliability.
AI Post 🪙 | Our X 🥇

It’s time to move beyond the pilot phase and integrate intelligence into the core architecture for measurable business outcomes. https://www.cio.com/articl...

Unlocking the full potential of enterprise AI means moving beyond experimentation to integrating AI profitably – by ensuring complete and trusted access to data wherever it resides, breaking down silos, and creating a unified data architecture that drives faster insights, reduces risk, and maximizes return on investment for enterprises ready to lead in the A https://www.cio.com/articl...

The story of intelligence, both human and artificial, is, at its core, the story of how we build meaning through collaboration. When I first stepped from https://aijourn.com/the-na...

The improving demand for this chip designer's architecture could send its revenue and profits soaring in the long run. https://www.fool.com/inves...

MindHYVE.ai™, a leader in artificial general intelligence (AGI) technologies, announced a landmark partnership with the California Institute of Artificial Intelligence (CIAI) to revolutionize global AI education through adaptive, agentic learning systems. The collaboration unites MindHYVE's Ava-Fusion™ reasoning architecture and ArthurAI™ learning platform with CIAI's mission to make https://finance.yahoo.com/...

Image generators are designed to mimic their training data, so where does their apparent creativity come from? A recent study suggests that it's an inevitable by-product of their architecture. https://www.livescience.co...

This company's chip architecture is gaining traction in multiple AI-powered smart devices. https://www.fool.com/inves...


https://youtu.be/0OHuQfX7E...
#pastelitos #paste #pastelgoth #blackandwhite #beautiful #family #pastelpainting #amazing #pastelaria #pastelaesthetic #pasteles #aesthetic #black #arte #pasteup #pasteldrawing #fashion #intags #pasteleriaartesanal #pastelcolours #artwork #cat #artist #pastelcolors #architecture #art #anime #baby #pasteleria #amor
#pastelitos #paste #pastelgoth #blackandwhite #beautiful #family #pastelpainting #amazing #pastelaria #pastelaesthetic #pasteles #aesthetic #black #arte #pasteup #pasteldrawing #fashion #intags #pasteleriaartesanal #pastelcolours #artwork #cat #artist #pastelcolors #architecture #art #anime #baby #pasteleria #amor
Felicitări tuturor cu ajunul sărbătorilor de Paște. Pace sănătate și fericire . - YouTube
При финансовой поддержке
HUYAQ NET
3 годы назад
Trattoria Villa
Da oltre 40 anni la vostra trattoria di fiducia

